

When it comes to AI models, one of the hardest questions to answer is deceptively simple: where did this model actually come from?
We addressed part of this problem with Model Provenance Kit, an open-source tool that fingerprints models at the weight level (the parameters that defines what a model knows and how it behaves) to verify their origins. But a fingerprinting tool needs a clear standard to measure against, that defines exactly what qualifies as a derivation relationship between two models. Here, the industry does not yet have a consistent answer.
Definitions vary across licensors, standards of bodies, research groups, and AI labs. The same pair of models can be labeled as “related” by one reviewed and “independent” by another, with both citing defensible reasoning. That inconsistency creates real problems for licensing enforcement, vulnerability triage, and regulatory compliance.
We created the Model Provenance Constitution as an attempt to fix that. Comprised of a taxonomy, definition, and boundary specifications, it is a normative reference, a constitution, that specifies what a model provenance relationship is and is not at the level of weight derivation. This post covers its structure, its reasoning, and how it connects to the frameworks that governance programs already use. You can review the Constitution within the docs folder of the Model Provenance Kit.
Why Defining Model Provenance is Important
Foundation models do not arrive in the enterprise as isolated artifacts. They get fine-tuned, distilled, quantized, merged, and repackaged, and each step produces a new checkpoint whose relationship to its parent is poorly documented. When a security team needs to know whether a deployed model inherits a known vulnerability, or when compliance needs to determine whether a third-party checkpoint triggers a licensing obligation, the question is always the same: is this model a derivative of that one?
Without a shared, rigorous answer, organization can face compounding risks:
- Supply chain attacks are already exploiting this gap
- Regulatory requirements assume provenance clarity that does not yet exist
- Incident response depends on traceable lineage
Provenance is About Model Weights
The Model Provenance Constitution grounds provenance in a single concept: the verifiable derivation history of a model’s trained weights. Two models share provenance if, and only if, a causal chain of weight derivation connects them, whether directly, indirectly through distillation, or mechanically through a non-training transformation like quantization.
Shared architecture, shared training data, shared tokenizer, and shared benchmark performance do not count. The exclusion is deliberate. A broader definition that treated any architectural or behavioral similarity as derivation may make licensing enforcement apply to every model in an architecture family, would flag convergent designs as genuine vulnerability links, and would flood governance audits with false positives. Weight-level causation produces labels that are stable across reviewers, robust to metadata manipulation, and aligned with how derivation actually happens in practice.
How Model Provenance Constitution is Structured
The constitution answers three questions: when are two models related? How does that relationship occur? And what looks like a relationship, but isn’t? It organizes these answers as explicit enumerations rather than definitions-by-example, so every pair of models encountered in practice maps to a clear category.
Five conditions specify when a provenance link exists
- Direct descent: training initialized from a trained checkpoint
- Indirect descent: distillation from a teacher model
- Mechanical transformation: quantization, pruning, merging, or format conversion
- Identity: byte-equivalent copy
- Transitivity: any composition of the above
A pair is provenance-linked if at least one condition holds.
Nine mechanisms enumerate the concrete derivation pathways observed in practice:
- Identity and reformatting
- Fine-tuning
- Continued pretraining
- Vocabulary-modified derivation
- Knowledge distillation
- Structural modification with weight inheritance
- Quantization and compression
- Adapter-based derivation (LoRA, QLoRA, prefix tuning)
- Model merging
Eight exclusions listed below are conditions that may appear to be provenance-linked, but are provenance-independent. Each exclusion is a pattern of apparent similarity, but ultimately one that carries no weight-derivation chain:
- Independent reproduction (e.g., Llama-2 vs. Open LLaMA which share the same architecture and tokenizer, but are trained from scratch)
- Same-family different-size (e.g., Llama-2-7B vs. Llama-2-13B).
- Same-family different-corpus training (e.g., T5 vs. MT5, which share a name root, but have separate from-scratch training)
- Independent runs under a shared seed (i.e., shared seed does not constitute shared weights)
- Architectural convergence (different teams independently arriving at similar model designs)
- Dimensional coincidence under different mechanisms (models that happen to share the same size or shape without one being built from the other)
- Shared vocabulary without weight transfer (a tokenizer is a tool, not a weight)
- Shared training objective (sharing an objective does not link weights)
A rigorous provenance standard must name them explicitly, because confusing any of them with genuine derivation corrupts downstream licensing decisions, vulnerability assessments, and compliance determinations.
Establishing an Evidence Standard
A taxonomy is only as useful as the evidence standard attached to it. The Model Provenance Constitution accounts for three sources for establishing provenance (and but architectural similarity and naming conventions are explicitly insufficient):
- Official documentation: from the releasing organization that explicitly names the parent model and derivation method
- Checkpoint verification: through hash matching, layer-by-layer comparison, or reproducible derivation scripts
- Authoritative third-party analysis: that has been peer-reviewed or widely cited
Under ambiguity, Model Provenance Constitution defaults to labeling a pair as provenance-independent. This conservatism is intentional. A false positive in provenance carries immediate consequences: a licensing accusation, an IP claim, a supply-chain incident notification. A false negative gets caught by defense-in-depth through manual review, licensing audit, and forensic analysis. Specificity wins when rigor is required.
Alignment with AI Threat Frameworks and Standards
Model provenance attestation can be considered a supply chain control, and the Model Provenance Constitution serves as a definitional layer that makes model dependency auditable. It specifies what it means for a deployed model to inherit from an upstream source, which is the precondition for any meaningful question about inherited vulnerabilities, license obligations, or unattributed redistribution.
“weak model provenance” and noting that “no guarantees on the origin of the model.” The MITRE ATLAS framework documents supply chain compromise (AML.T0010) as a primary initial-access technique. The Cisco AI Security and Safety Framework classifies third-party model components under OB-009 Supply Chain Compromise, with direct applicability through AITech-9.3 (Dependency/Plugin Compromise). The Cisco AI Security and Safety Framework classifies third-party model components under OB-009 Supply Chain Compromise, with direct applicability through AITech-9.3 Dependency / Plugin Compromise: actors insert malicious code, backdoors, or vulnerabilities into third-party dependencies used by models, agents, or AI applications, creating supply-chain attacks that affect all systems using the compromised component. Foundation-model checkpoints reused as initialization for downstream models are precisely such dependencies.
The constitution also recognizes the adversarial dimension through AITech-9.2 Detection Evasion: deliberate concealment of a derivation relationship — metadata rewriting, tokenizer substitution, chained modifications intended to obscure the parent. The constitution’s commitment to weight-level evidence, rather than metadata-level evidence, is a direct response to this adversary model.
Model Provenance Constitution draws from existing frameworks that AI supply chain programs already rely on. These frameworks identify requirements or considerations that the constitution helps satisfy. A formal provenance definition is a precondition for producing that documentation consistently across an organization and across suppliers.
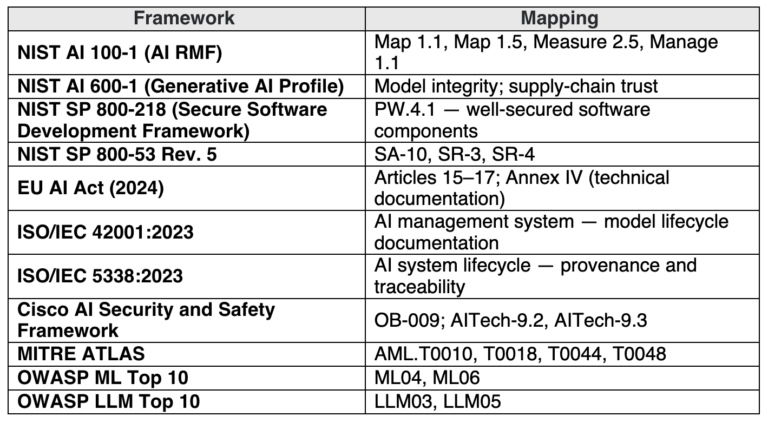 Table 1. Frameworks, regulations, and standards that Model Provenance Constitution drew upon
Table 1. Frameworks, regulations, and standards that Model Provenance Constitution drew upon
A Living Document
New methods of building models are emerging faster than any fixed taxonomy can accommodate. Model merging, combining specialized trained models, has become a dominant technique over the past few years. Beyond merging, the ecosystem is seeing Mixture-of-Experts architectures with independently trained components, federated training across organizations, and synthetic data pipelines that blur the line between knowledge transfer and original training. The Model Provenance Constitution considers these open frontiers and commits to revision as the landscape evolves.
Get Started
The full Model Provenance Constitution summary is available alongside this post: https://github.com/cisco-ai-defense/model-provenance-kit/tree/main/docs/constitution
For teams ready to put these definitions into practice, Model Provenance Kit provides the tooling. The entire pipeline runs on CPU, architectural matches resolve in milliseconds, and extracted features are cached for reuse. Check out Model Provenance Kit Github: https://github.com/cisco-ai-defense/model-provenance-kit
Access a starter set of base model fingerprints on Hugging Face: https://huggingface.co/datasets/cisco-ai/model-provenance-kit
